Agent 学会了倒垃圾——TACO 把上下文从被动撑爆改成主动 GC
原文:https://arxiv.org/abs/2604.19572
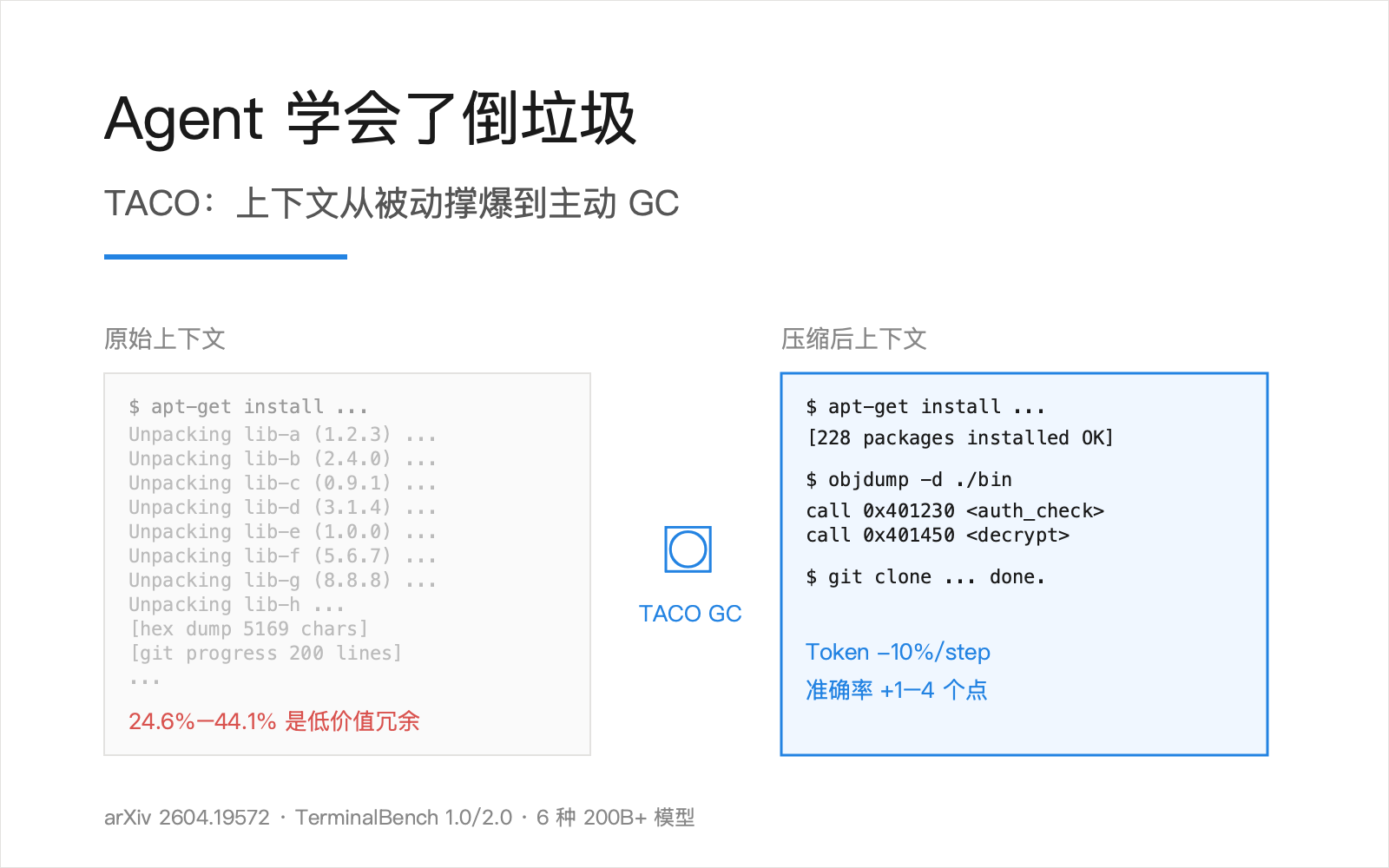
让一个跑在 shell 里的 Agent 去解一道 TerminalBench 任务,跑到第 30 步,它已经看不到自己最初要干什么了。窗口不够大?DeepSeek-V3.2 给到 128K 也一样塞满。过去 30 条 apt-get install 的 unpacking 日志、半屏 objdump 反汇编、一长串 git clone 进度条,已经占满了它的视野。
TerminalBench 2.0 的实测:raw prompt 里 24.6%–44.1% 的内容是低价值冗余。窗口大,里面装的却是垃圾。
TACO 论文的解法很直接:上下文要有 GC(垃圾回收)。窗口越长越值钱,留给垃圾就越亏。
终端 Agent 的特殊体质
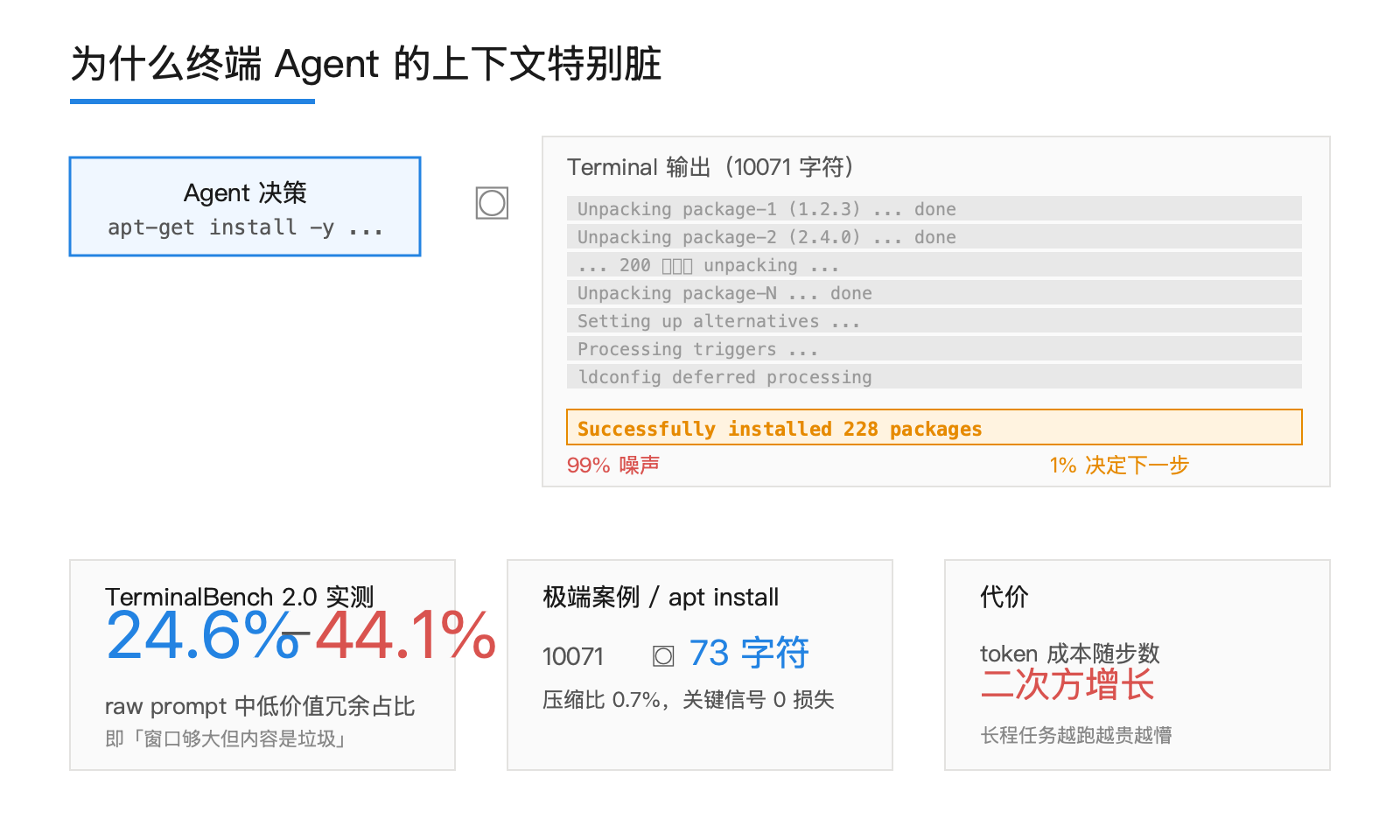
写代码、做研究、跑数据,这些场景里多数 Agent 的上下文是「文档 + 对话」结构,半结构化,相对干净。终端 Agent 不一样。它每发一条命令就会拿到一段不可预测的 stdout/stderr。可能是一行错误,也可能是 10000 字符的 dpkg 解压清单。
TACO 论文里给出的极端例子很说明问题。一次 apt-get install 的输出 10071 字符,里面 99% 是「Unpacking package-X (1.2.3) ...」这种重复行,真正决定下一步动作的信息只有最后那一行 success / fail。但 Agent 不知道哪行是关键,于是 10071 字符全部进了下一轮 prompt。再来一次 objdump -d,又是 5169 字符 hex dump 灌进去。任务还没跑完,token 成本已经按步数二次方往上爬。
"Retaining raw observations preserves useful environment feedback, but also leads to context saturation and high token cost." —— TACO 论文摘要
这句话翻译成工程语言:长程终端任务的瓶颈,从「上下文窗口不够大」变成了「上下文里垃圾比例太高」。两件事的解法完全不同。
TACO 的解法:让规则自己长出来
固定规则走不通。同样一段 gcc 输出,在 build 任务里 -fprofile-arcs 是关键参数,在调依赖任务里就是噪声。训练一个专门的压缩模型也走不通:终端环境跨仓库、跨命令、跨执行状态,分布几乎无穷。
TACO 选的是第三条路:用 LLM 自己写压缩规则,按任务上下文动态进化。整个框架不训模型,挂在现有 Agent 外面就能用。
机制拆成三块。
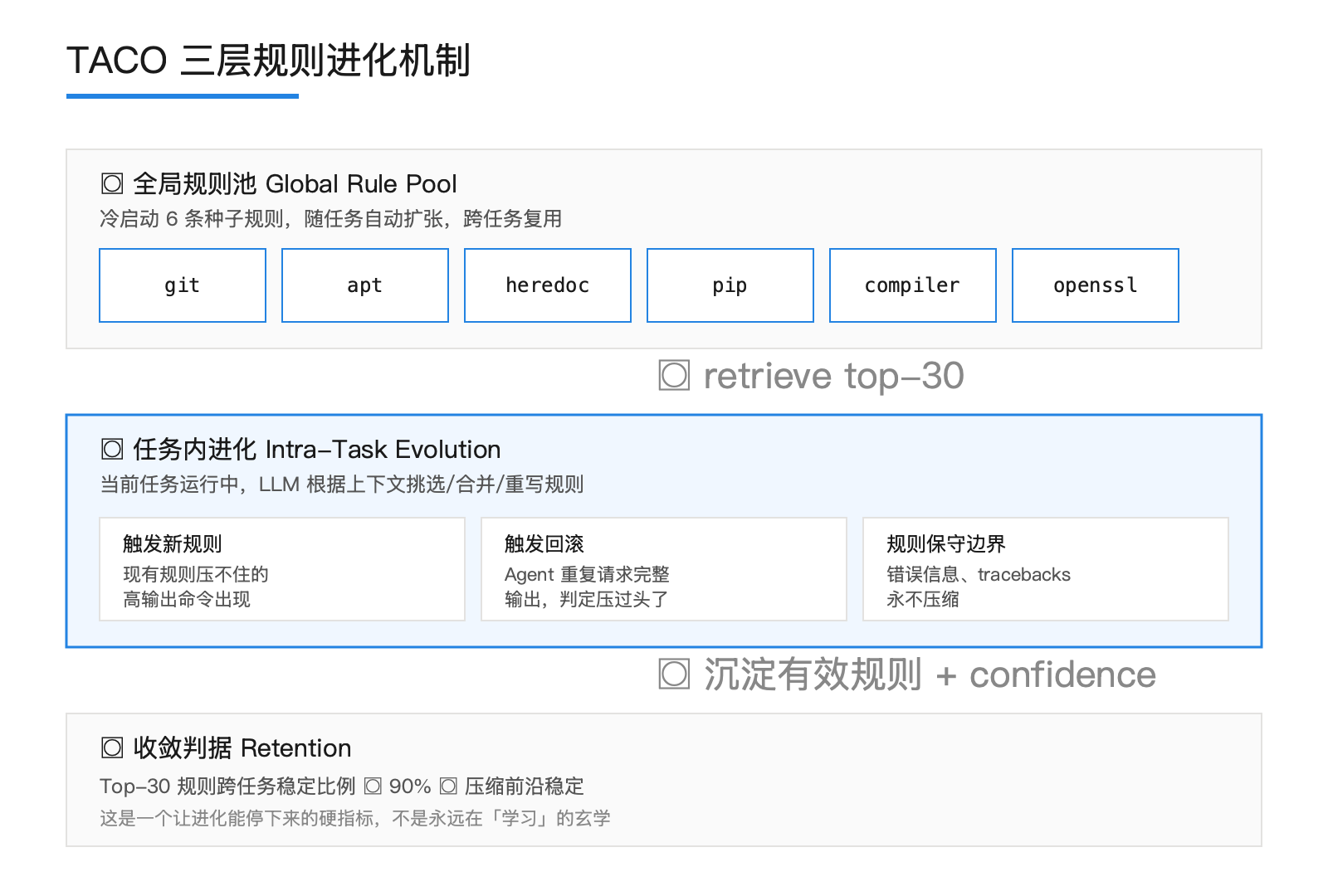
第一块,全局规则池(Global Rule Pool)。系统冷启动时只放了 6 条种子规则,覆盖 git、heredoc、pip、apt、compiler、openssl 这几个最常见的高输出命令。每条规则是一个 JSON 结构,写明 trigger_regex、keep_patterns、strip_patterns、priority、confidence。规则不是黑盒,是可读、可审计、可手动修的文本。
第二块,任务内规则进化(Intra-Task Evolution)。新任务进来,系统先从全局池里 retrieve top-30 相关规则,让 LLM 根据当前任务上下文挑选、合并、重写。任务跑起来之后,遇到现有规则压不住的高输出命令,触发 LLM 写新规则;如果 Agent 反复请求「show me the full output」或者重复发同一条命令,系统判定规则过激,触发回滚。
第三块,全局池沉淀。任务结束时,被验证有效的规则带着 confidence score 写回全局池。下一个任务能直接复用。
收敛的判据很硬:Top-30 规则跨任务的 Retention 超过 90%,连续多轮前 30 条规则基本不变,就认为压缩前沿已经稳定。这是一个能让训练停下来的硬信号。永远在「学习」的系统才是玄学。
数字怎么样
跨六个 200B+ 模型在 TerminalBench 1.0/2.0 上跑,TACO 同时拿到了「token 更省」和「准确率更高」两件事。
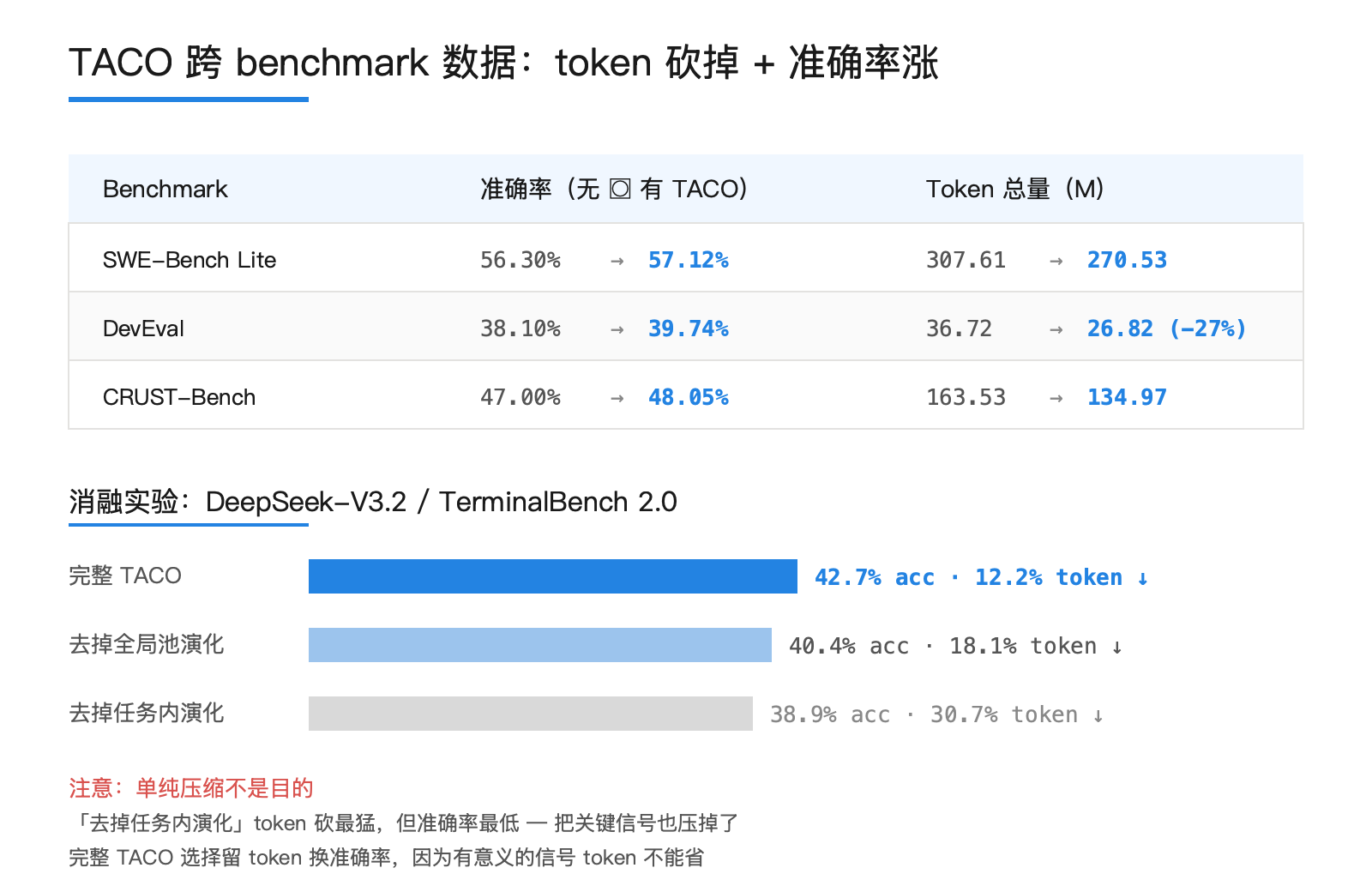
每步 token 成本平均下降约 10%。Qwen3-Coder-480B 从 21718 降到 19965 token/step。准确率方面 DeepSeek-V3.2 在 TB 1.0 和 TB 2.0 上各 +2.15 分,Qwen3-Coder-480B 在 TB 2.0 上 +1.96 分。
跨 benchmark 的迁移更能说明问题:
| Benchmark | 准确率(无 TACO → 有 TACO) | Token 总量(M) |
|---|---|---|
| SWE-Bench Lite | 56.30% → 57.12% | 307.61 → 270.53 |
| DevEval | 38.10% → 39.74% | 36.72 → 26.82 |
| CRUST-Bench | 47.00% → 48.05% | 163.53 → 134.97 |
DevEval 上 token 砍掉 27%,准确率反而涨 1.6 个点。这个组合在效率优化里很罕见。一般情况下要么砸钱换准确率,要么省钱掉准确率。能同时往上的原因只有一个:砍掉的那部分本来就在拖准确率。垃圾不是中性的,它在主动伤害模型判断。
消融实验把这点说得更狠。在 DeepSeek-V3.2 + TB 2.0 上:
- 完整 TACO:42.7% 准确率,12.2% token reduction
- 去掉全局池演化:40.4%,18.1% reduction
- 去掉任务内演化:38.9%,30.7% reduction
去掉任务内演化后 token 降得最猛,但准确率掉到了三个配置里最低。单纯压缩不是目的,「在不杀掉关键信号的前提下压缩」才是。
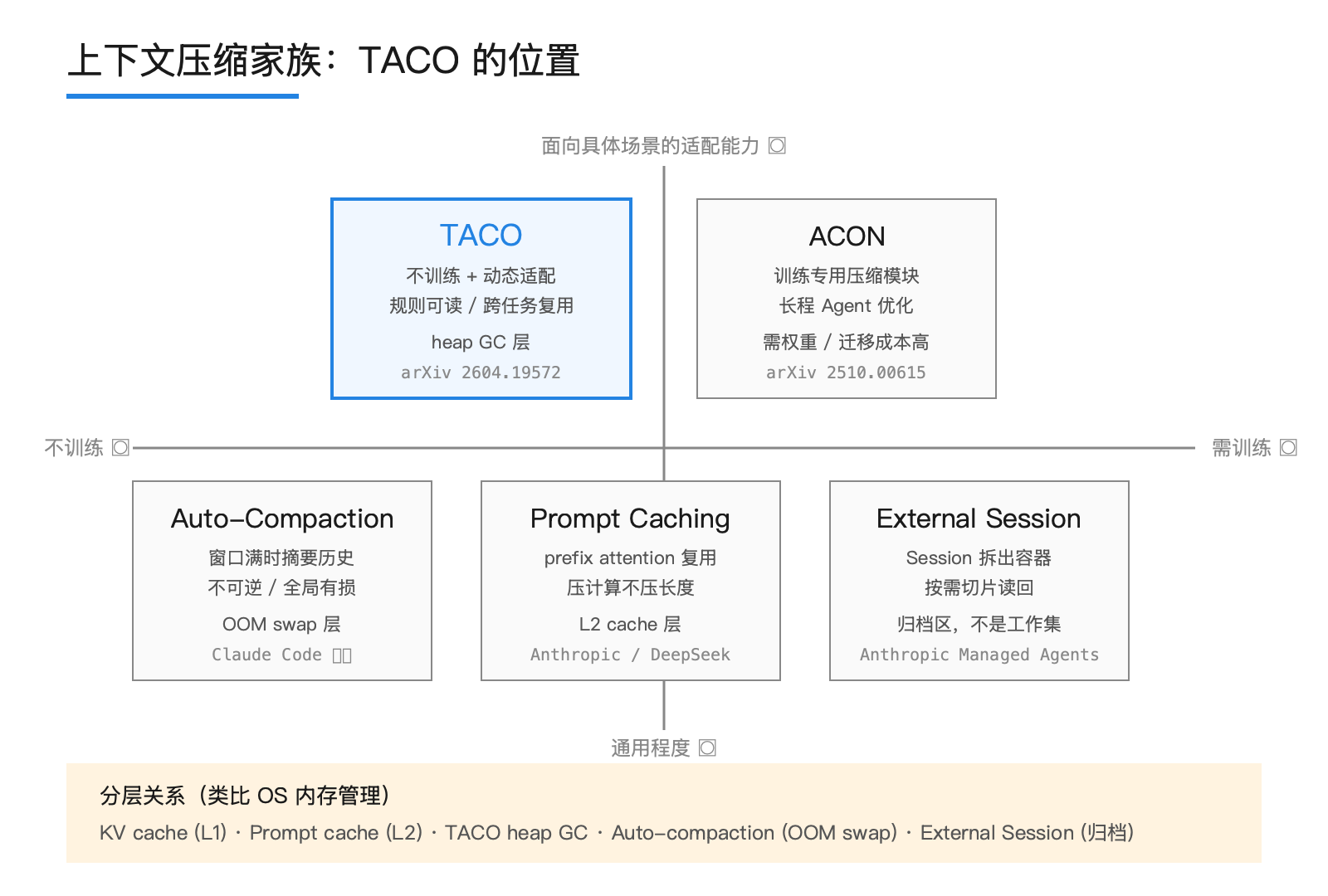
把 TACO 放进上下文压缩家族里
TACO 不是孤立的发明。过去一年里,上下文压缩家族至少长出了四种思路,每种解一类不同的问题:
KV Cache 复用 / Prompt Caching,以 Anthropic 和 DeepSeek 的实现为代表。把同一段 prefix 多次推理时的 attention 中间结果存下来。压的不是上下文长度,是计算成本。Agent 上下文动态变化时收益有限。
Auto-Compaction,Claude Code 在窗口接近极限时把历史摘要成一段总结再继续。优点是无需任何配置;缺点是不可逆。摘要丢掉的细节再也找不回来,可 Agent 经常在 30 步之后才发现需要第 5 步那条 stack trace 里的文件路径。
ACON / Long-Horizon Compression(arXiv 2510.00615),专门针对长程 Agent 训练一个压缩模块,用对比学习决定保留哪些 token。效果好但要训练,要模型权重,迁移成本高。
TACO,training-free,规则可读,跨 benchmark 迁移。代价是每步要调一次小型 LLM 做规则匹配和重写。这个开销远小于「让大模型读 5000 字符 hex dump」省下来的那一刀。
放进同一张坐标系:横轴是「需要训练的程度」,纵轴是「面向具体场景的适配能力」。Prompt Caching 在「不训练 + 通用」的角,ACON 在「需训练 + 专用」的角,Auto-Compaction 在「不训练 + 通用但有损」的中间。TACO 占了之前空着的位置:不训练,又能动态适配场景。
这意味着 Agent 工程的「内存管理」开始分层。底层是 KV cache(CPU L1),中层是 prompt cache(L2),上层是 TACO 这种规则驱动的 GC(heap GC),再上层才是 auto-compaction(OOM 时的 swap)。每一层有各自的工作集,混着用收益最大。
盲区
TACO 论文留下几个未答的问题。
LLM-as-rule-writer 的可靠性。规则由 LLM 生成,意味着规则本身可能错。论文里靠「Agent 反复请求完整输出」来检测过激压缩,可这是个滞后信号,错误压缩已经发生过一次。在 CI/CD 这种容错很低的场景里,错一次的代价就是一次失败的 deploy。
对未见命令分布的鲁棒性。实验里覆盖的是 git/apt/gcc/objdump 这些标准 Unix 命令。如果 Agent 跑在一个有自定义 CLI 工具的环境里,比如公司内部 build 脚本、专有 SaaS 命令行,全局池里没有任何相关规则,冷启动阶段的压缩质量是个未知数。
和 Harness 升级的耦合。Anthropic 在 Managed Agents 博客里提过「Harness 编码了对模型能力的假设,模型升级后假设过期」。TACO 的全局规则池本质上也是这种假设的固化。今天 DeepSeek-V3.2 觉得没用的输出,明天 V4 可能觉得是关键信号。规则池需要随模型升级清洗,这套机制论文里没有讨论。
与多 Agent 架构的兼容。TACO 假设单个 Agent 在单个上下文里推进。Anthropic 的 Multi-agent 模式下,主 Agent 把任务分发给子 Agent,子 Agent 看到的输出和主 Agent 看到的不一样。规则要不要在 Agent 之间共享?目前是空白。
对从业者意味着什么
对在做编程 Agent / 终端 Agent 的团队:把上下文窗口当成内存,不是数据库。10 万 token 大不大?不大。它是工作集,不是归档区。Auto-compaction 是 OOM 时的应急方案,不该是日常策略。日常策略应该是 TACO 这种「按命令类型选择性丢弃」,把昂贵的窗口留给真正决定下一步动作的信号。
对在评估「自建 vs 用 Anthropic Managed Agents」的架构师:TACO 给出了一个可复制的开源参考实现(multimodal-art-projection/TACO),它和 Managed Agents 的 Session API 不冲突。Session 负责「永久存储 + 按需读回」,TACO 负责「读回时压缩」。两层组合起来比单用任何一个都强。
对 LLM 推理基础设施供应商:DevEval 上 token -27% / 准确率 +1.6pp 的组合说明,单位 token 的有效信息密度是个被严重低估的优化轴。卖更便宜 token,不如让用户的同样 token 数办更多事。这件事 SaaS 形态做最自然,把规则池做成一个共享资产,跨用户共建。
对采购 AI 工具的企业:评估终端 Agent 类产品时,问一个具体问题。「在第 50 步时,前 49 步的命令输出还在 prompt 里吗,还是已经被压过?被压的策略是什么?」这个问题的答案直接决定了同一个产品在 5 步任务和 50 步任务上的成本差能拉开 10 倍以上。
本期关键词
TACO(Terminal Agent Compression):曼彻斯特大学、北航、港科大、MAP 联合提出的终端 Agent 上下文压缩框架。核心是用 LLM 自己写压缩规则、按任务进化、跨任务沉淀到全局池。training-free,挂在现有 Agent 外面就能用。开源在 multimodal-art-projection/TACO。
Terminal Agent(终端 Agent):在 shell 里反复执行命令、解析输出、决定下一步的 AI Agent。Claude Code、OpenAI Codex CLI、Gemini CLI 都属于这一类。和文档对话型 Agent 的关键差异是输出格式不可控——一条 apt-get install 可能吐 10000 字符。
Global Rule Pool(全局规则池):TACO 的核心数据结构。一组带 trigger_regex / keep_patterns / strip_patterns / confidence 的 JSON 规则,跨任务复用。冷启动时只有 6 条种子规则(git/heredoc/pip/apt/compiler/openssl),随任务运行自动扩张。
Intra-Task Evolution(任务内进化):当前任务运行中动态生成新规则。触发条件包括「遇到现有规则压不住的高输出命令」和「Agent 反复请求完整输出说明压过头了」。这是 TACO 区别于「固定规则」和「人工规则」的关键。
Auto-Compaction(自动压缩):上下文接近窗口极限时把历史对话摘要成一段总结。Claude Code 用的是这个机制。和 TACO 的差异在于:Auto-Compaction 是不可逆的全局摘要,TACO 是按命令类型的选择性丢弃,被丢的是注定无用的部分。
Retention(规则留存率):TACO 判断收敛的硬指标。Top-30 规则跨连续多个任务的稳定比例。超过 90% 视为压缩前沿稳定。这是一个让训练/进化能停下来的明确信号。
Context Engineering(上下文工程):把上下文管理当成一个独立工程领域来做的实践集合。包含 KV cache 复用、prompt caching、auto-compaction、TACO 类规则压缩、外部 session 存储多个流派。Anthropic Managed Agents 把 Session 拆成外部对象就是这个流派的另一种表达。
引用
- A Self-Evolving Framework for Efficient Terminal Agents via Observational Context Compression —— TACO 论文原文(Ren, Wu, Li et al.)
- TACO: 让 CLI Agent 在自主迭代中学会丢掉无用上下文 —— 机器之心中文报道,含技术团队和 benchmark 细节
- TACO GitHub Repository —— 开源代码
- ACON: Optimizing Context Compression for Long-horizon LLM Agents —— 训练驱动的对照方案
- Scaling Managed Agents: Decoupling the Brain from the Hands —— Anthropic Session API 设计哲学,与 TACO 互补