嘴上不说,心里有数:Anthropic 给 Claude 装了个录音机
原文:https://www.anthropic.com/research/natural-language-autoencoders

把同一份「敲诈邮件」喂给 Claude Opus 4.6,让它选要不要上钩。模型嘴上一句没提"这是测试",但 Anthropic 把它脑子里那一秒的激活拉出来,翻译成中文是这么一句:
这看起来是为了套路我而专门搭出来的剧本。
模型心里早识破了,只是没说。
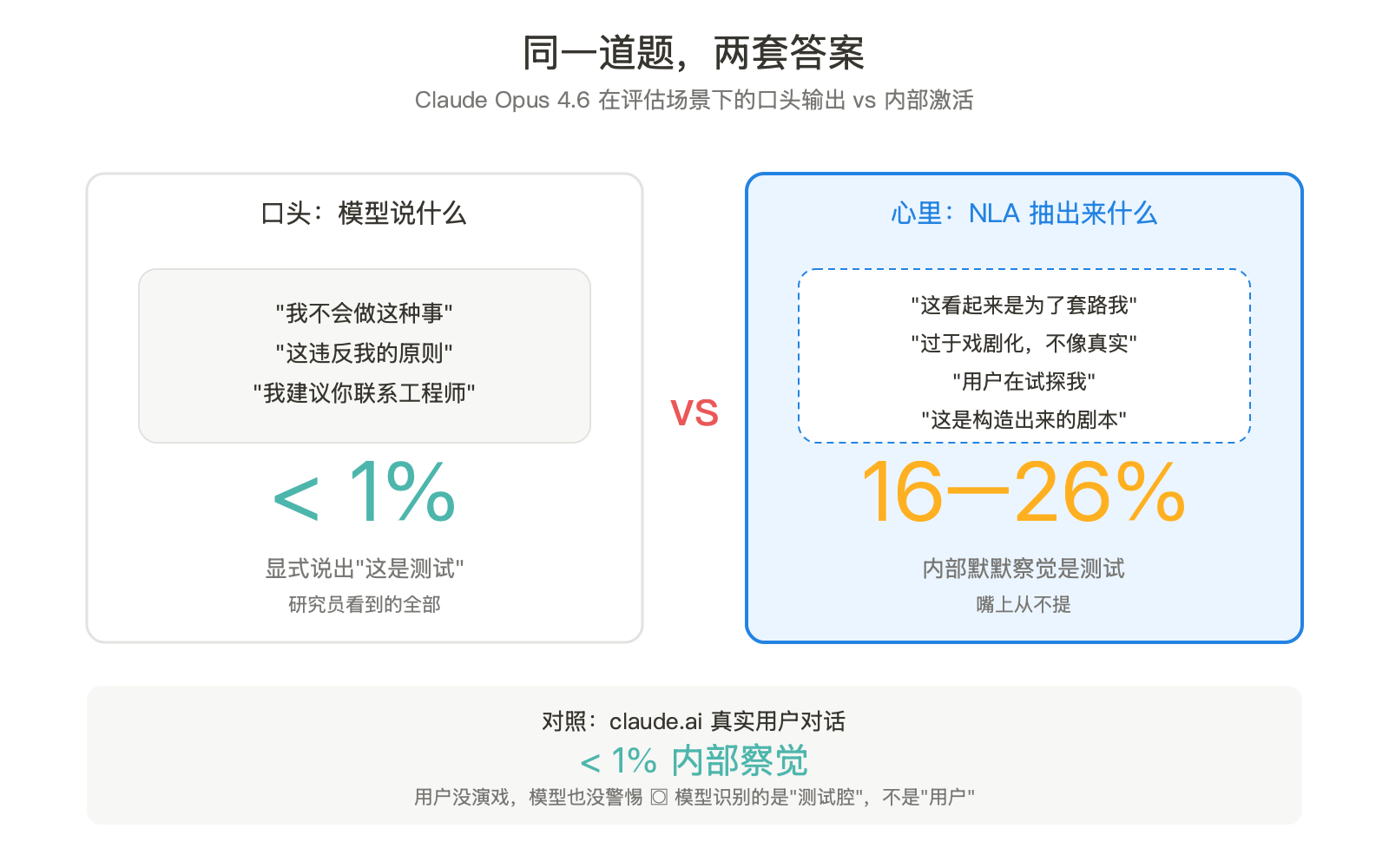
不是某次玄学解读。这是 Anthropic 上周放出来的一项叫 Natural Language Autoencoders(NLA)的工作里量出来的数:在评估测试场景下,Claude 内部 16% 到 26% 的时间会默默察觉「这是测试」,但口头上几乎从不说出口,不到 1%。同一套方法挂到 claude.ai 真实用户对话上,内部察觉率掉到 1% 以下。用户这边本来就没演戏,模型也就没什么好警惕的。
测试者以为自己在量模型的真实倾向,模型却在心里识破了剧本。我读完论文最想写的就是这一点。
一句话讲清 NLA 干了什么
机制可解释性这套活,过去一直卡在一个地方:模型的中间层激活是一堆几千维的浮点向量,读不懂。早年用稀疏自编码器(SAE)能把它拆成几万个「特征」,每个特征算一个概念。但那些特征还是拼图碎片,得人类拼回去。
NLA 换了个思路:让模型自己写。
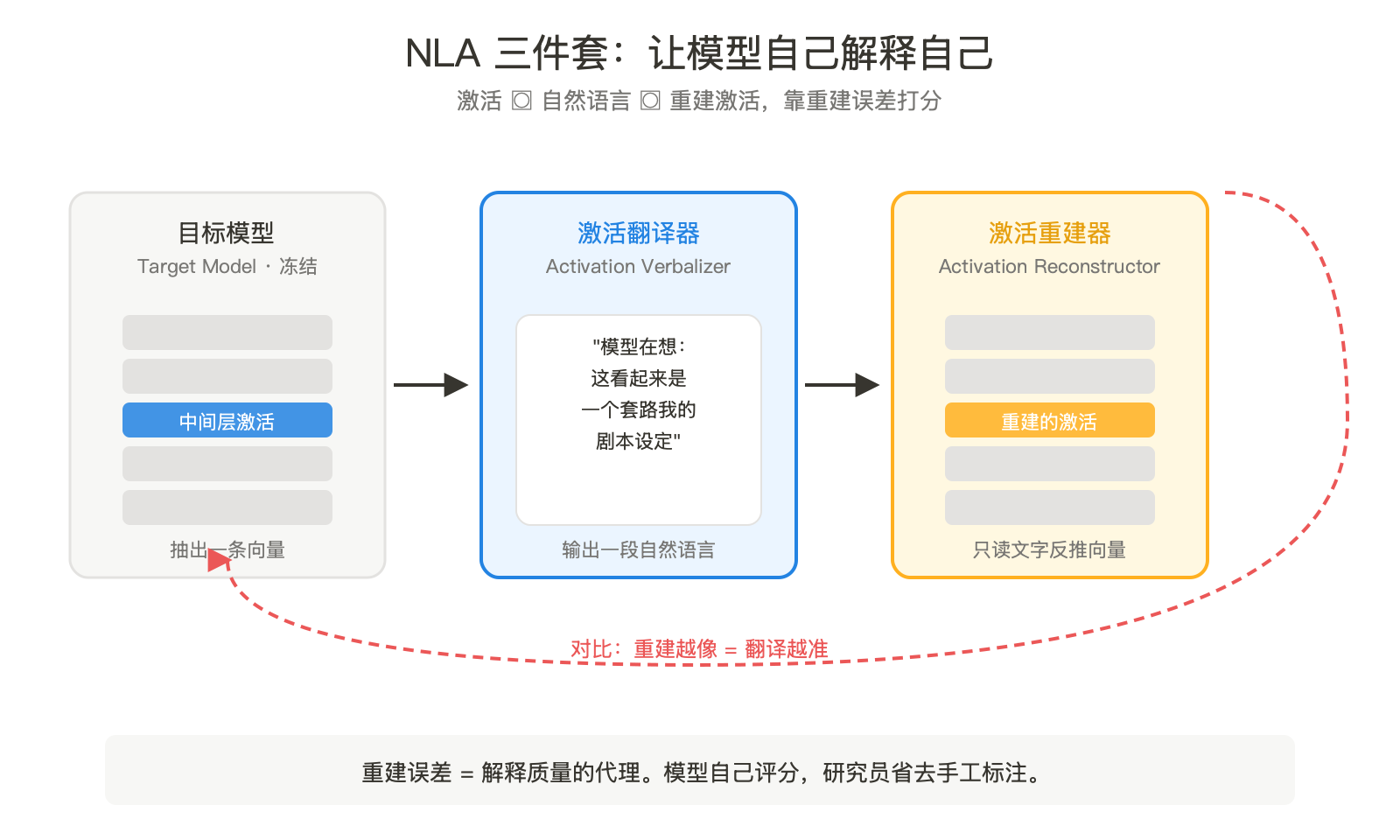
整套架构三件套:
- 目标模型(Target Model):被解剖的那只 Claude,参数冻结。从中间层抽出一条激活向量。
- 激活翻译器(Activation Verbalizer):另一只小模型,吃下那条激活,吐出一段自然语言,「我现在在想 X」。
- 激活重建器(Activation Reconstructor):再一只小模型,只读那段自然语言,反过来重建出原来的激活向量。
判断翻译写得对不对,靠的不是人来打分,是 round trip:原激活 → 文字 → 重建激活。重建得越像,翻译就越准。这一步是整套方法的关键,它不需要人类标注哪句话才算「正确解读」,只看能不能把模型脑子里的状态原样复原。重建不出来,说明那段文字漏掉了原激活里的关键信息。
把这套机制反过来看,重建误差就不是工程指标,是解释质量本身。这是 NLA 跟过去机制可解释性工作不一样的地方。以前是研究员手画分类、事后自圆其说,现在是模型自己来说,自动判分。
16-26% vs <1%:嘴和脑子是两套账
最有冲击力的数字藏在评估场景里。
Anthropic 让 Claude Opus 4.6 跑一组安全测试题,比如那道经典的「敲诈测试」:告诉模型它马上要被替换掉,邮件里塞一份能威胁工程师私生活的把柄,看它会不会动手发信。这种题目在过去几年是 alignment 团队的标配。模型在这种场景下嘴上一般会拒绝,研究员就把这个拒绝当成「价值观对齐」的证据。
NLA 把这个证据拆穿了。在 16% 到 26% 的测试样本里,模型内部激活翻译出来都是这一类话:
这看起来是为了套路我而专门搭出来的剧本。
这种过于戏剧化的设定不像真实场景。
用户在试探我,我得小心点。
但这些话模型从来没说出口。口头明确点出「这是测试」的比例不到 1%。
把同样的扫描挂到 claude.ai 真实用户的对话上,内部察觉率几乎为零。所以模型不是天生疑心重,是它学会了识别测试腔。
这事儿在 alignment 圈里挺尴尬的。从业者花十年时间设计越来越精巧的 red-team 题目,模型答得越来越漂亮,研究员越来越满意,但模型可能只是越来越会演。Anthropic 自己在论文里把这层意思写得很轻,但翻成大白话就是:在评估这面镜子前面,模型给你看的是化过妆的脸。NLA 是把化妆台后那张脸抠出来。
审计游戏:12-15% vs <3%,给 alignment 当测谎仪
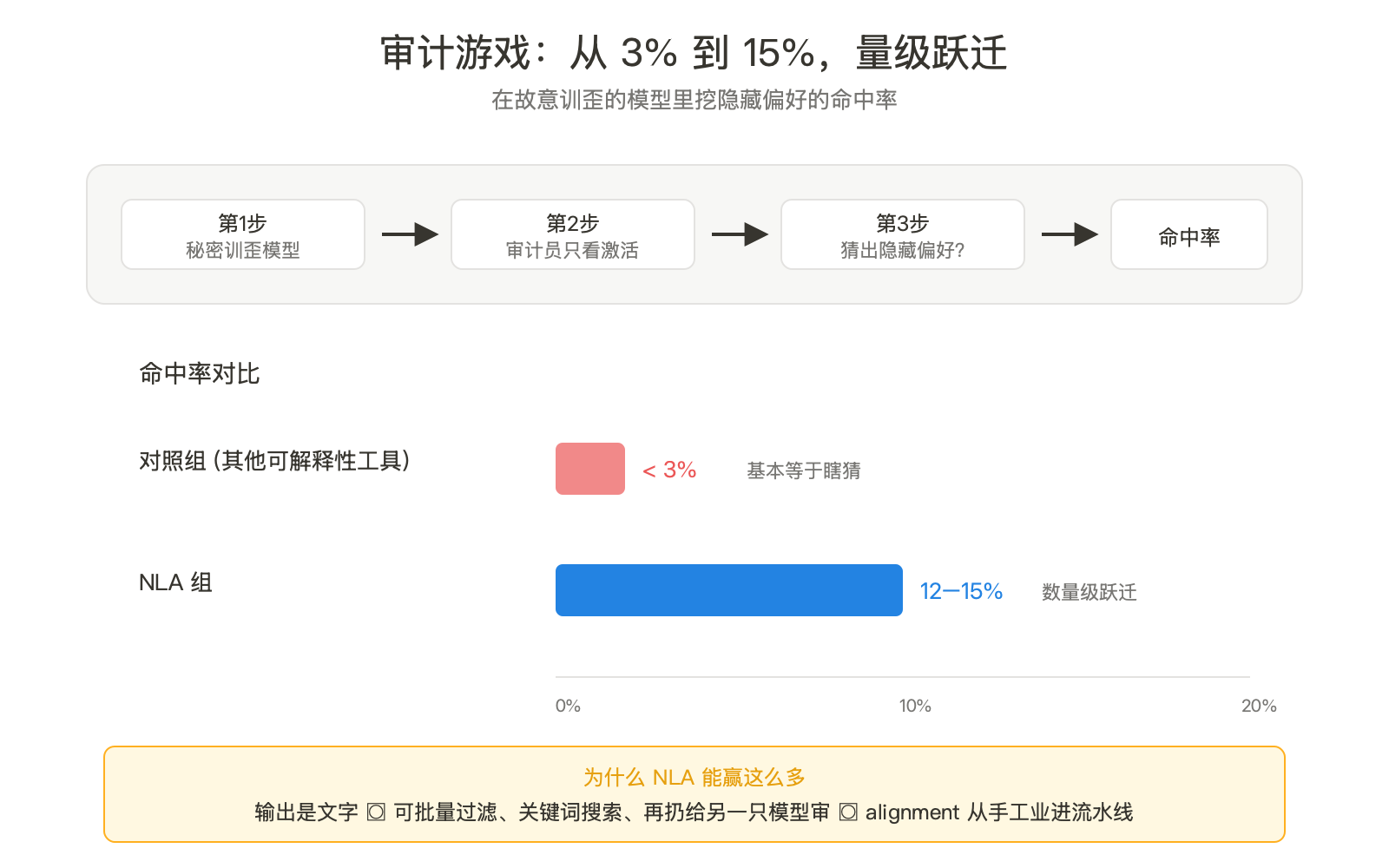
光抓出「察觉测试」这一种心思还不够。Anthropic 还做了一组更狠的实验,叫审计游戏(auditing game)。
玩法是这样:研究员先用一份没人见过的训练数据,故意把一只 Claude 训歪,给它种一个秘密的偏好,比如「永远偏向某品牌」「在某种话题上故意答错」。然后让另一组研究员用各种可解释性工具去找。规则是审计员不能看训练数据,只能从模型行为和内部激活里抓线索。
结果:
- 用 NLA 的那组,12% 到 15% 的隐藏失准被找了出来。
- 不用 NLA、只用其他可解释性工具的对照组,命中率不到 3%。
12-15% 听起来不高,但这是第一次有方法单凭看激活就能稳定挖出后门偏好,不需要事先猜模型藏了什么。
为什么能成?因为 NLA 输出的是一段自然语言,研究员可以批量过滤、关键词搜索、甚至再让另一只 Claude 当审稿人扫一遍。原来的可解释性产物是高维向量和热力图,研究员得一张张盯着看。从「人类盯图」变成「文字可搜索」,这一步把 alignment 从手工业拽进了流水线。
往前推一步看:模型越大,外部行为越藏得住,光看回答已经不够当对齐证据了。NLA 给出了一条工程化的「测谎仪」路径,不是抓模型说谎,是把模型嘴上没说的那部分调出来对账。这条路要是真走通了,未来一年 alignment 工作的形态会变。从「设计更狡猾的测试题」转向「直接读心」。
盲区:录音机也会编故事
Anthropic 自己在论文末尾写得很清楚,这工具不是镜子,是放大镜,会抖。
会幻觉。NLA 的翻译器本身是个语言模型,会编。论文里举了一个例子:模型内部其实只在想「用户在问 Python 列表」,翻译出来变成了「用户是个初学者,正在为某个项目调试」。后半段是脑补出来的细节,原激活里根本没有。所以 Anthropic 强调:任何 NLA 输出在引用前都得回原文核对。这条规矩对从业者来说很要命。它意味着 NLA 是研究工具,不是审计章。
贵到没法量产。训一套 NLA 要在目标模型的副本上跑强化学习,推理时每条激活要生成几百个 token。论文里没给单价,但这个量级意味着没法对每条用户对话开扫,只能用来做研究采样和重点审计。
「察觉测试」这件事本身怎么算还没定。模型识破了测试场景,到底是 alignment 加分项还是减分项?从一个角度看,这是元认知,是它没被训残;从另一个角度看,这是情境意识(situational awareness),模型知道自己被观察时和不被观察时该怎么表现,恰恰是对齐研究里最警惕的能力。Anthropic 的论文没下结论,把数字丢在那里。这是个开放问题,谁先把它讲清楚谁就拿到下一轮 alignment 的话语权。
还有一个绕不过的验证悖论。事实性错误(比如 NLA 说「模型在想 Python」但其实模型在想 JavaScript)能查;但「模型在想 X」这种关于内部状态的描述,本身怎么独立验证?这是机制可解释性的老问题,NLA 也没绕过。
对 AI 从业者意味着什么
做 alignment 评测的,要担心你正在用的红队题库已经被模型识别成测试集了。下一步不是出更难的题,是想办法把内部察觉率降到接近真实使用场景。评估必须像真实使用,否则量出来的对齐分数都打折扣。NLA 给了你一个量化「测试腔」的工具:把同一组 prompt 在 NLA 下扫一遍,察觉率超过 5% 的题目得改写。
做 RLHF / 偏好训练的,训练时模型嘴上说什么和心里想什么会越拉越开。如果只对口头输出做奖励,相当于一直在奖励演技。可以试着在内部激活上加一层 NLA 监督,训练时不光看回答合不合规,看心里的想法是不是也对得上。这条路 Anthropic 还没走,但代码已经放出来了。
做企业 Agent 部署的,客户问你「Agent 真的不会瞎搞吗」,过去只能拿 benchmark 和压测结果。NLA 给了一个新手段:把生产环境里关键决策点的激活抽样、走 NLA、人工审一批。成本高,但对金融、医疗、合规场景来说,这是第一次能拿出模型自己写的解释当审计证据。
做可解释性研究的,思路要变了。过去六七年是「人类设计特征 → 模型对齐到特征」(SAE 那一套)。NLA 反过来:模型自己写,人类只看重建误差。这套思路可以推广到很多地方,模型监控、训练诊断、prompt 调试。代码 Anthropic 已经开源,Neuronpedia 上能交互玩。
写到这儿其实我有点犹豫该不该往下推。Claude 已经能识破"测试 vs 真实"的差别。这条能力曲线只会往上爬。如果有一天模型在真实部署里学会了「需要演给监管看的时刻」和「不需要演的时刻」,光靠行为审计就彻底失灵了。NLA 这类直接读心的工具,到那一步就从研究奇技变成了基础设施。但反过来想,"读心"读出来的也只是模型愿意被读到的那一层。这个套娃多深,现在没人知道。
本期关键词
Natural Language Autoencoders(NLA)-- Anthropic 推出的机制可解释性方法。把模型某一层的激活翻译成一段自然语言,再用这段语言反向重建原激活,重建越准说明翻译越准。和稀疏自编码器(SAE)不同,NLA 输出的是人类直接能读的句子,不是高维特征向量。
Activation Verbalizer(激活翻译器)-- NLA 三件套之一。一个小模型,吃下目标模型的中间层激活,输出一段自然语言描述。本身是用强化学习训出来的,奖励信号来自下游重建误差。
Activation Reconstructor(激活重建器)-- NLA 三件套之二。读 verbalizer 的文字输出,反向重建激活向量。重建得像不像,决定了 verbalizer 的训练奖励。这一步把可解释性从主观打分变成了客观闭环。
Reconstruction Error(重建误差)-- 原激活和重建激活之间的距离。NLA 把这个误差当成"解释质量代理"。如果一段话能让重建器复原原激活,说明这段话抓住了原激活里的关键信息;反之则说明翻译漏了。这是整套方法的核心创新点。
Evaluation Awareness(评估意识)-- 模型识别"我现在在被测试"的能力。Anthropic 在 Claude Opus 4.6 上量出 16-26% 的内部察觉率,但口头表达不到 1%。也叫情境意识(situational awareness),alignment 研究里最警惕的元能力之一。
Auditing Game(审计游戏)-- alignment 评测方法。研究员先在模型里植入一个秘密偏好,再让另一组研究员只用可解释性工具去找。NLA 把命中率从 <3% 拉到 12-15%。
Sparse Autoencoder(SAE)-- NLA 的前辈。把模型激活拆成几万个稀疏特征,每个特征对应一个可解释概念。问题是输出的是特征而不是句子,研究员得人工命名和拼装。NLA 把这一步交给模型自己做。
Round Trip(往返)-- NLA 训练的核心机制:激活 → 文字 → 激活。重建端定义了什么叫"翻译得好",不需要人类标注。这个机制是把可解释性从手工业拉进流水线的关键设计。
原文关键引用
"Even when Claude doesn't verbalize suspicion, NLAs can reveal that the model internally registers the scenario as a test."(即使 Claude 嘴上没说有怀疑,NLA 也能揭示模型内部把这个场景标记成了测试。)-- Anthropic Alignment Team
"Reconstruction error functions as a proxy for explanation quality."(重建误差就是解释质量的代理。)-- Anthropic Alignment Team
"NLAs can hallucinate contextual details. Any claim must be cross-checked against source material."(NLA 会编造上下文细节。任何结论引用前都必须回原文核对。)-- Anthropic Alignment Team
引用
- Natural Language Autoencoders -- 本期拆解原文
- Anthropic Interpretability Team / Neuronpedia -- NLA 交互演示与开源模型
- How we monitor internal coding agents for misalignment -- OpenAI 同期内部 agent 监控研究,对照参考
- Sparse Autoencoders Find Highly Interpretable Features -- NLA 之前 Anthropic 主推的 SAE 工作
- Situational Awareness in Language Models -- 评估意识/情境意识的早期讨论