15 个人挤进文生图前三:Luma 把"图里写字"做成了护城河
原文:https://lumalabs.ai/news/uni-1-1-api
在一份只有 OpenAI 和 Google 两家公司的榜单上,挤进第三名的难度,比拿第一还高。
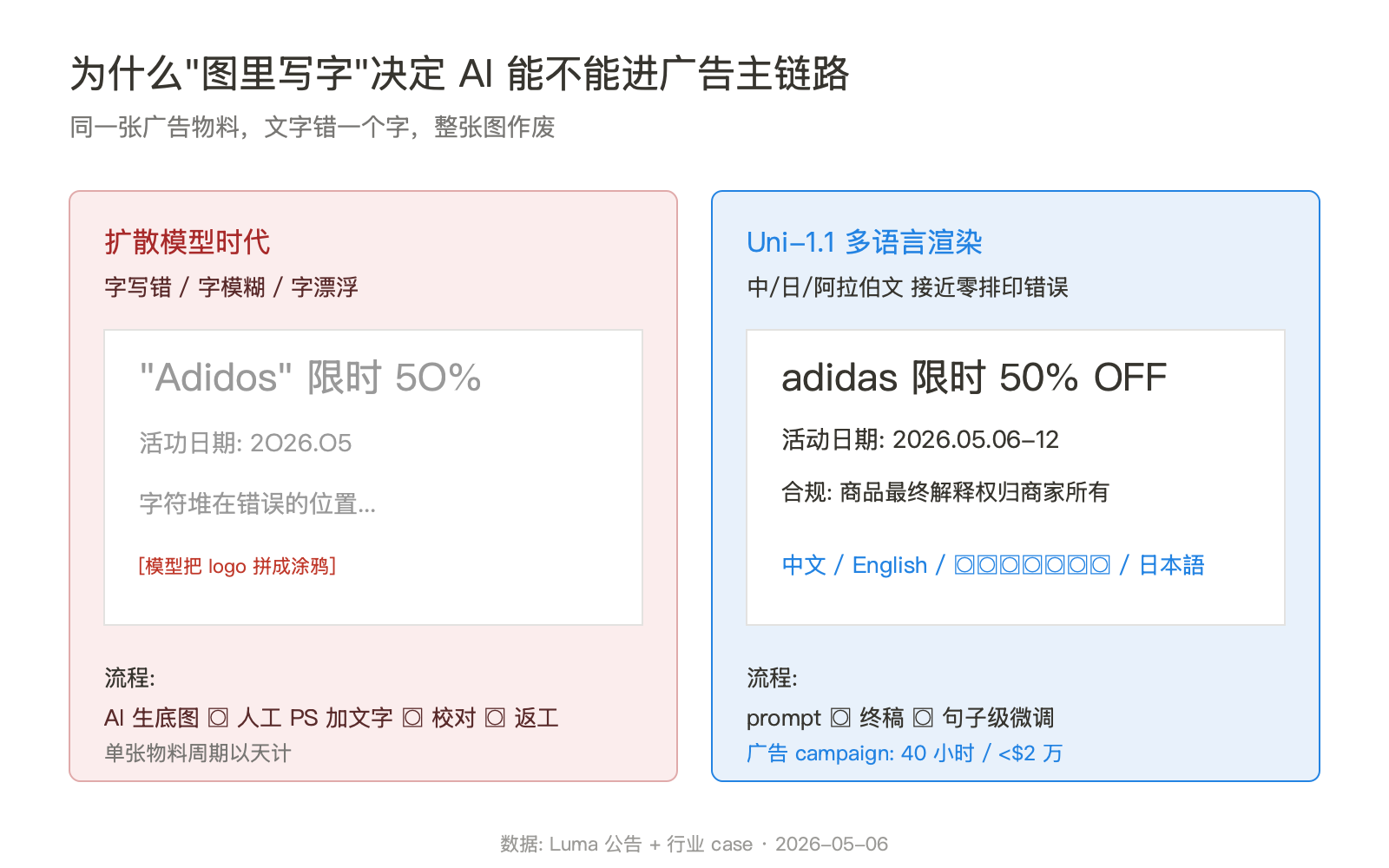
5 月 6 日,Luma 把 Uni-1.1 的 API 推上货架。Arena.ai 的盲测榜上,它的 ELO 是 1193,前面是 GPT-Image-2 和 Nano Banana 2,再往下是所有人。一支不到 15 人的团队,用一年时间把图像模型做到了全球第三,而且把价格压到同类的不到一半,单张推理 31 秒。
更值得停下来看一眼的,是这家公司选的发力点:图里写字。
文字渲染:广告生意的硬门槛
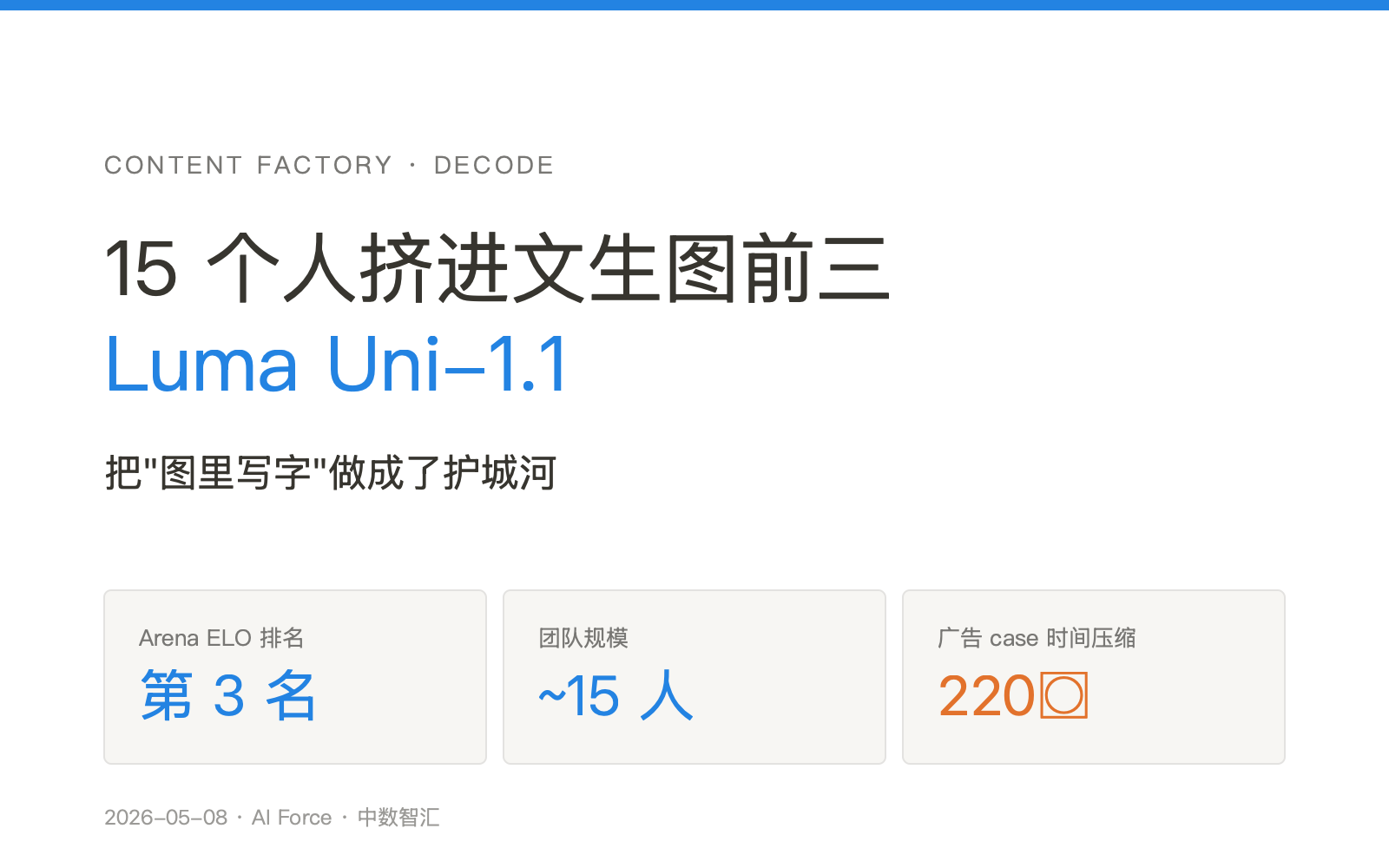
绝大多数文生图模型都把字写错。Midjourney 写英文像在涂鸦,Stable Diffusion 写中文像在刻甲骨,连 GPT-Image-1.5 也只在英文短句上勉强过关。Luma 的 Uni-1.1 把这件事单拎出来作为发布卖点:原生多语言渲染,覆盖中文、日文、阿拉伯文、英文,"接近零排印错误"。
这是奔着企业客户去的。
阿迪达斯、马自达、阳狮集团、Serviceplan 已经在用 Uni-1.1 跑广告物料。这类客户的需求和 C 端用户截然不同——一张广告图里要有品牌 slogan、产品名、价格标签、活动日期、合规小字。任何一个字渲染错误,整张图就废了。在 GPT-Image-2 出现之前,4A 公司的标准流程是 AI 生底图、人工 PS 加文字。Uni-1.1 把这一步省了。
广告行业里现在流传一组数据:一个原本预算 1500 万美元、周期一年的 campaign,用 Luma Agents 跑了 40 小时、花了不到 2 万美元,多国本地化版本一次性完成,过了甲方内审。750 倍成本压缩、220 倍时间压缩——这种数字在视频生成领域出现过,但在静态图和版面上是头一回。
把字写对了,AI 才真正能接广告制作的主链路。否则永远只能停在"找灵感"这一步。
decoder-only 自回归 Transformer:把文字和像素塞进同一条序列
Uni-1.1 在架构上做了一个赌注:放弃扩散模型的主流路径,走 decoder-only 自回归 Transformer。
这是 GPT 系列的架构,不是 Stable Diffusion 的架构。
差异在哪?扩散模型的工作方式是从一团高斯噪声里"雕刻"出图像,文字 prompt 通过 cross-attention 注入。文字和像素活在两个世界,靠交叉注意力握手。这种设计擅长产出视觉效果惊艳的画面,短板是逻辑推理。你让它画"三个苹果,左边一个被咬了一口",它经常给你两个苹果或四个,咬痕长在错的位置。
Uni-1.1 把文字 token 和图像 token 混进同一条序列,用同一个 forward pass 处理。Luma 官方原话:"Text and images are represented in a single interleaved sequence, acting both as input and as output."文字和像素被等价对待。
模型因此可以在生成像素之前先做推理。要画一张包含报头、导航、广告位、正文段落的复杂版面?先在内部"想"一遍布局,再开始落像素。要写一段中文标语?每个汉字进入 token 序列,享受和英文 token 同等的处理路径,而非被压成一团抽象的视觉特征。
这能直接解释 Uni-1.1 为什么在 RISEBench(专测时间、因果、空间、逻辑四类视觉推理)上刷到第一。画得更漂亮不见得,但下笔之前想得更清楚。
代价是慢。31 秒一张图,比扩散模型的 5-10 秒慢得多。Luma 的解法是降价——Build 计划下,2048 像素文生图的价格区间是 $0.0404 到 $0.1000,"价格与延迟均不到同类模型的一半"。慢但便宜,对企业批量生产的场景来说划算。

9 张参考图:把"风格"变成 API 参数
Uni-1.1 相对 Uni-1 最实用的升级是参考图数量从单张提到 9 张。
听起来是个数字游戏,落地完全不是。
3 张以下的参考图本质是"风格迁移"——告诉模型大概要哪种调性。9 张参考图允许的是"组件化生成":第一张是品牌 logo,第二张是产品本体,第三张是模特,第四到六张是场景,第七到九张是配色和材质参考。模型把这些拆开理解,组装成一张新图,每个元素的可控性都由参考图锁定。
这是把"美术指导"这个角色 API 化了。过去广告公司里有一道工序叫"做 mood board"——把几十张参考图钉在墙上,让设计师参照。9 张参考图就是把 mood board 直接喂给模型,让它替你做合成。
配合上句子级编辑("把背景换成黄昏""光线再柔一点""把这个 logo 放到右下角"),工作流从"生成—筛选—返工"变成"生成—直接微调"。返工不再要求重抽整张图,改一句话就行。
对企业客户来说,这两个特性叠加才是真正的卖点。文字渲染解决"图能不能用"的问题,9 张参考图加句子级编辑解决"图能不能改"的问题。两件事都做对了,AI 生图才能进生产流程。
15 个人和两位华人
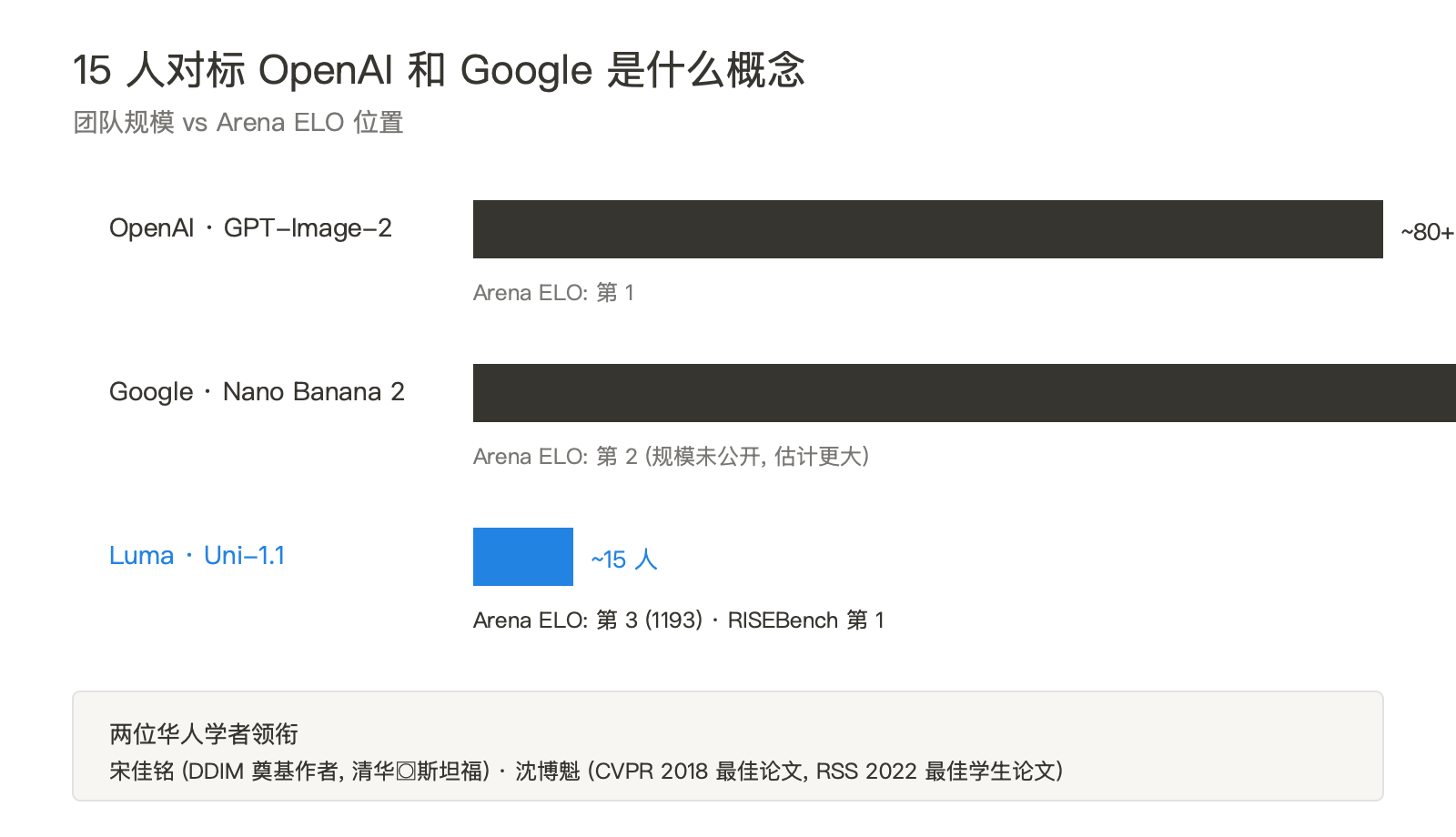
Luma 自己披露的团队规模是 15 人左右,由两位华人学者领衔。
宋佳铭,清华本科、斯坦福博士,是 DDIM(Denoising Diffusion Implicit Models)的奠基作者——这篇论文是扩散模型采样加速的标志性工作,引用过万。沈博魁,斯坦福本博,CVPR 2018 最佳论文奖、RSS 2022 最佳学生论文奖。两位都是从扩散模型路线出来的人,最后做出 Uni-1.1 这种自回归架构,本身就是一种姿态——他们不是不会做扩散,是判断扩散到顶了。
15 个人对标 OpenAI 和 Google 是什么概念?OpenAI 的 GPT-Image 团队保守估计 80 人以上,Google 的 Imagen/Nano Banana 团队规模未公开但显然更大。Luma 的策略是用架构选择对冲规模差距:选一条对手不愿意走的路(自回归在图像生成上有训练成本和推理速度的劣势),把这条路走透,避免和大厂在主流路径上拼算力。
同样的剧情在视频生成领域演过一次。Luma 之前的产品是 Dream Machine,靠精挑路线在 Sora 和 Veo 之间挤出一席之地。Uni-1.1 是同一个剧本的第二集:避开主流路径上和巨头硬碰,找一个被低估的方向打透。
榜单第三的位置只是表层。真正的信号是:一个被认为已经被 OpenAI 和 Google 锁死的赛道上,新玩家依然能用 15 人和一年时间打出存在感。这一点对独立 AI 实验室的意义,比 ELO 多 50 分要大得多。

盲区与未说出口的
Uni-1.1 的发布故事很顺,但有几个口径还没对上。
**ELO 1193 和 RISEBench 第一不是同一件事。**Arena.ai 的 ELO 反映用户盲测的整体偏好,Uni-1.1 在这个榜上是第三。RISEBench 测的是逻辑推理类编辑能力,Uni-1.1 在这个榜上是第一。两个榜单测的不是一回事。Luma 的对外口径把 RISEBench 第一放在最显眼的位置,把 Arena 第三放在补充说明,这是一种合理的取景策略,但企业客户需要看清楚自己的场景到底落在哪个榜上。
**31 秒推理时间在生产场景的意义未明。**官方坦承速度是劣势,并用价格补偿。但广告 campaign 一次要出几百到几千张图。31 秒乘以 1000 是 8.6 小时——这种延迟在交互式产品里完全不可用,在批处理里也算长。Luma 没有公布并发上限和批量优惠的细节。
**自回归图像生成的训练成本曲线未公开。**Diffusion Transformer 的 scaling law 已经被反复验证,自回归图像模型的边际效益还在试探阶段。Uni-1.1 能不能在下一代模型上继续保持架构优势,取决于这条曲线长什么样。如果训练成本随分辨率指数级膨胀,15 人团队的故事就讲不下去了。
**"价格只有 Nano Banana 零头"是团队自评。**官方对外的对比数字是"价格与延迟均不到同类模型的一半",更克制。这两个口径之间的差异值得追问——零头和一半是 5 倍的差距。
对 AI 从业者意味着什么
如果你在做企业级图像生成产品:文字渲染能力的重要性会持续被低估,直到客户拿着印错品牌名的废稿来找你。把"图里写字"作为模型选型的一级指标,而不是次级特性。Uni-1.1 在中文场景下的表现尤其值得测——这是 GPT-Image-2 和 Nano Banana 2 的相对短板。
如果你在评估文生图技术路线:扩散模型不再是默认答案。自回归路线在 2026 年开始拿到实证:RISEBench 上的推理优势、复杂版面的可控性、文字渲染的精度,这些都不是扩散模型靠"再调一调"就能追上的能力。选型时把推理类任务和生成类任务分开评估。
如果你在做广告或营销内容:40 小时 vs 一年的对比意味着工作流要重写。AI 生图从"找灵感"的辅助工具升级成直接产出物料的主链路。二阶效应(4A 公司的人员结构、客户的预算分配、媒介的供给节奏)比模型本身的进步更值得追。
一个更深层的信号:图像生成的竞争格局没有像很多人预期的那样收敛到 2-3 家。15 人团队靠选对架构进入前三,说明模型层的护城河比想象的浅。下一波竞争点会是"模型 + 工作流"。谁能把 9 张参考图、句子级编辑、Agent 编排打包成企业能直接用的产品,谁就能拿走那 1500 万美元变 2 万美元的差价。
本期关键词
Decoder-only 自回归 Transformer -- GPT 系列采用的架构。文字 token 和图像 token 排进同一条序列,用同一个 forward pass 处理,文字和像素被等价对待。这种设计的好处是模型在生成像素之前可以先做推理(先想后画),代价是推理速度比扩散模型慢。Uni-1.1 是少数把这条路线在图像生成上做到第一梯队的产品。
RISEBench -- Reasoning-Informed visual editing benchmark,专门测视觉推理能力的榜单。覆盖时间、因果、空间、逻辑四类编辑任务。和 Arena.ai 的偏好榜不是同一件事——后者测"用户更喜欢哪张",前者测"模型有没有理解 prompt 里的逻辑约束"。Uni-1.1 在 RISEBench 上排第一,在 Arena.ai 上排第三。
Arena.ai ELO -- 仿照国际象棋等级分体系的盲测榜单。两两对比让用户选偏好,按胜负累积分数。Uni-1.1 当前 ELO 是 1193,前面是 GPT-Image-2 和 Nano Banana 2。这个榜单的特点是反映"用户审美",不反映"任务完成度"。
句子级图像编辑 -- 不重新生成整图,只通过自然语言指令修改图像局部。"把背景换成黄昏""把这个 logo 放到右下角"。Uni-1.1 的句子级编辑配合 9 张参考图,让"返工"从"重抽"变成"局部改写",这是把 AI 生图从灵感工具变成生产工具的关键能力。
多语言文字渲染 -- 在生成的图像里准确写出可读文字,覆盖非拉丁字符(中文、日文、阿拉伯文)。这件事大多数文生图模型至今做不好。Uni-1.1 把它列为发布的一级卖点,因为它直接决定了模型能不能进入广告、电商、品牌物料的主链路。
DDIM -- Denoising Diffusion Implicit Models,扩散模型采样加速的奠基论文,作者是 Luma 的宋佳铭。背景信息是为了说明 Luma 团队对扩散路线非常熟悉,最后选择自回归架构是主动判断不是不会做。
引用
- Introducing the Uni-1.1 API: Intelligence You Can Direct. Aesthetic You Can Ship. -- Luma 官方发布博客
- UNI-1 Technical Specifications -- 架构与评测说明
- Luma AI 推 Uni-1.1:华人 15 人团队造出 AI 生图黑马 -- 团队背景与广告 case 来源
- Uni-1.1 - Luma AI 推出的新一代图像生成模型 -- 中文整理稿
- Luma AI launches Uni-1, a model that outscores Google and OpenAI while costing up to 30 percent less -- VentureBeat 报道
- Luma AI's new Uni-1 image model tops Nano Banana 2 and GPT Image 1.5 on logic-based benchmarks -- benchmark 对比