当你开始写 "MANDATORY",agent 就已经塌了
原文:https://bsuh.bearblog.dev/agents-need-control-flow/

5 月 7 日,一个叫 Brian 的开发者在 Bear Blog 上贴了 350 字,标题《Agents need control flow, not more prompts》。第二天上 HN 当日热帖,153 条评论。
文章短得像一张便签。但它说出了所有写过 agent 的人在凌晨三点调试时心里那句话:没人想再调一次 "IMPORTANT: do not skip step 3"。
一行字判定:你的 agent 是不是已经失控了
Brian 给的判定信号很干脆。当你开始在 prompt 里塞 MANDATORY、DO NOT SKIP、YOU MUST,说明 prompt engineering 这条路已经被你榨干了。
工程师之间心照不宣的尴尬时刻。你写了一个 agent,跑了 20 次有 3 次跳过验证步骤。你不去改架构,你去 prompt 里加了一行全大写的 MANDATORY: ALWAYS VALIDATE BEFORE WRITING。下一次跑,跳过的概率从 15% 降到 8%。你松了口气,部署上线。
Brian 的判断是,你刚才不是在调试,你在做语言学研究。你想用更强的措辞让一个非确定性系统变得确定。这条路天然有上限,因为大写字母没有更大写。
HN 上有人接得很狠:「prompt engineering 的尽头是把整本 RFC 抄进 system prompt」。这不是俏皮话。我看过的 agent 项目里,超过一半的 system prompt 都正在朝那个方向漂。

编程语言的类比:能用的语言不靠"建议"
Brian 用编程语言做了一个类比,整篇文章就立在这一句上:
想象一种语言,statement 只是给运行时的"建议",function 可能幻觉返回值。一旦程序变复杂,你根本没法 reason about it。
这就是 agent 系统的现状。每一个 prompt 步骤都是一条"建议性 statement",每一个 LLM 调用都是一个"可能幻觉的 function"。3 步、跑 1 次的时候,它工作。30 步、跑 1000 次的时候,它崩。
软件工程过去 60 年怎么处理"复杂度"?模块化组合。库、函数、递归。这套东西能扩展,是因为每一层都确定:你调一个 sort,它一定排序,不会今天排序明天给你写首诗。
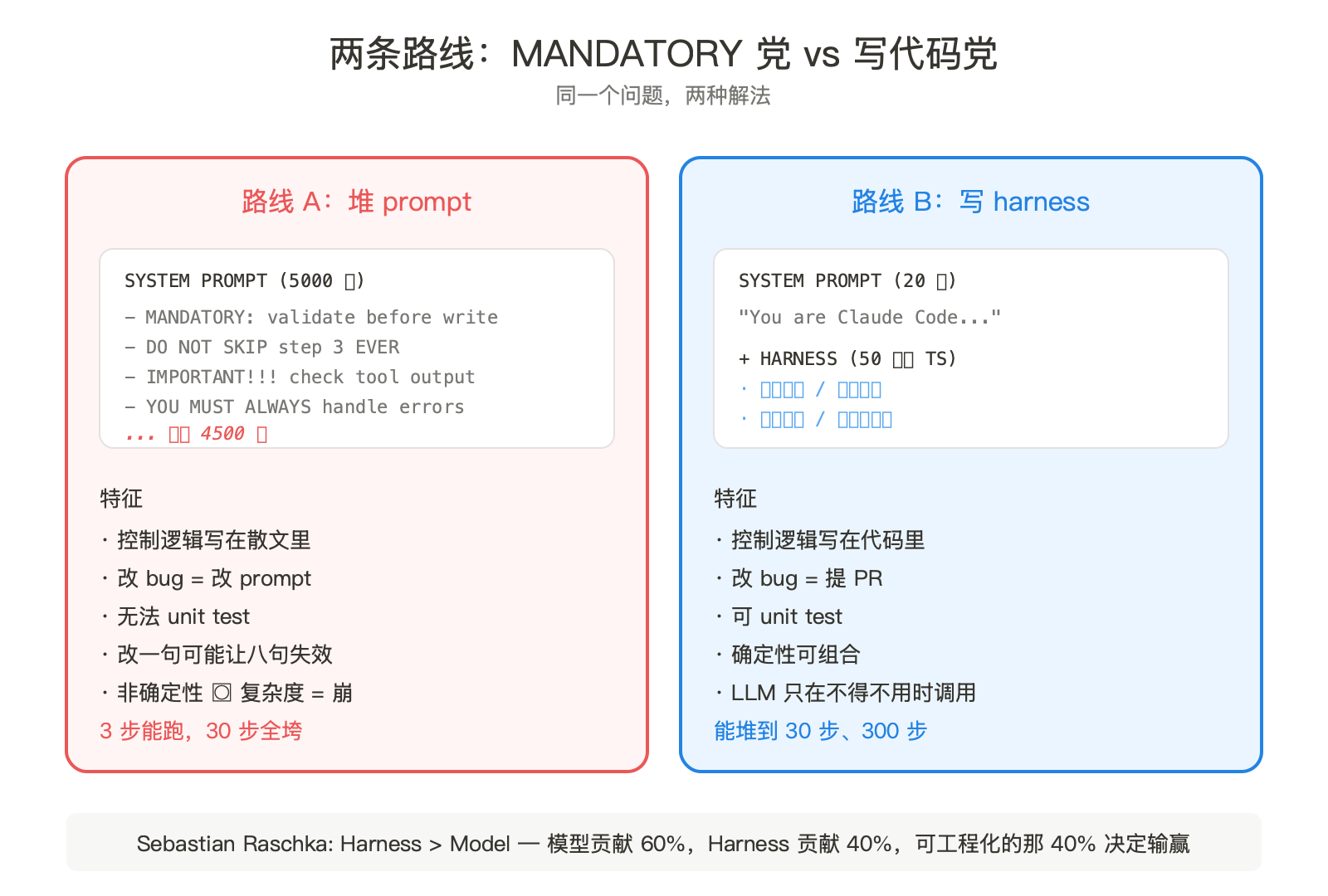
Prompt 链不是这个东西。Prompt 链是一段散文,散文里写着希望模型怎么做的指令。散文没有合约,散文不能 unit test,散文里加一句话可能让另外八句话失效。
Brian 的处方一句话:把逻辑从散文里搬进运行时。该用代码判断的地方用代码,该用 if-else 的地方用 if-else,把 LLM 留给真正需要语言能力的那一层。
这不是新观点,但它是现在最该被听见的观点
熟悉这个领域的人会想到 Anthropic 工程团队那篇 Building Effective Agents,会想到 Sebastian Raschka 提的 "Harness > Model",会想到 LangChain 这两年从"链式 prompt"被骂到现在主推 LangGraph 的轨迹。
Brian 没发明什么。他做的事是把分散在工程师 Slack、tweet、PR 评论里的共识,压成 350 个字。
我们自己的知识库里早就有 [[harness-engineering]] 这一页。模型贡献约 60% 的产品质量,Harness 贡献 40%。但那 40% 是可工程化、可积累、可竞争的。模型能力在头部三家之间趋同,Harness 是真正还能拉开差距的地方。
Claude Code 是这条路线最干净的活证据。整个 Claude Code 的 system prompt 只有 20 个词左右,复杂度全部压在执行层:50 万行 TypeScript,工具系统、权限管线、上下文压缩、子 agent 编排。代码搜索用 grep 不用向量,刻意选可靠性。
对照"MANDATORY 党"的做法。把整套权限规则、工具调用顺序、错误处理逻辑写进一个 5000 字的 system prompt,然后祈祷模型每次都听话。Claude Code 的做法是写代码。
谁更可靠?这不需要争。
反对派也不是没活:当编码逻辑反过来锁住你
公平起见,HN 上反对派的声音得听完。
最强的一种反对长这样。把控制流写死在代码里,等于给 agent 套上脚镣。你以为你在加确定性,其实你在用 2026 年 5 月你对这个任务的理解,去固化一个 2027 年才会跑的系统。模型升级了,你的 if-else 还在;任务边界变了,你的 scaffold 比 prompt 更难改。
我们在 managed-agents 拆解里写过的「Harness 保质期」就是这个张力。Harness 编码了关于模型能力的假设,假设会随模型进步而过时。Brian 这一篇没回答它。他默认了"任务的形状是稳定的、模型行为是要被驯服的",但真实世界里两边都在动。
第二种反对更钝。很多任务的形状你写不出 control flow。客服工单分流、长文写作、研究报告综述,你能给"判断这封邮件是不是抱怨"写一个确定性 scaffold 吗?写不出来。这种地方 LLM 就是核心决策器,不是更大确定性系统里的一个组件。
所以 Brian 的主张不是普适的银弹。它的适用场景是:任务的步骤可枚举,每一步可验证,错误的代价不可接受。代码生成、数据 ETL、自动化运维、多步 API 编排,这些地方该写代码就写代码。开放式认知任务该让模型当主角就让它当主角。
混着用才对。问题是现在大量 agent 项目把开放式认知任务的写法套用到本该写 control flow 的场景里。这才是 Brian 真正在骂的事。
三层防护:你只能选一种,没第四种
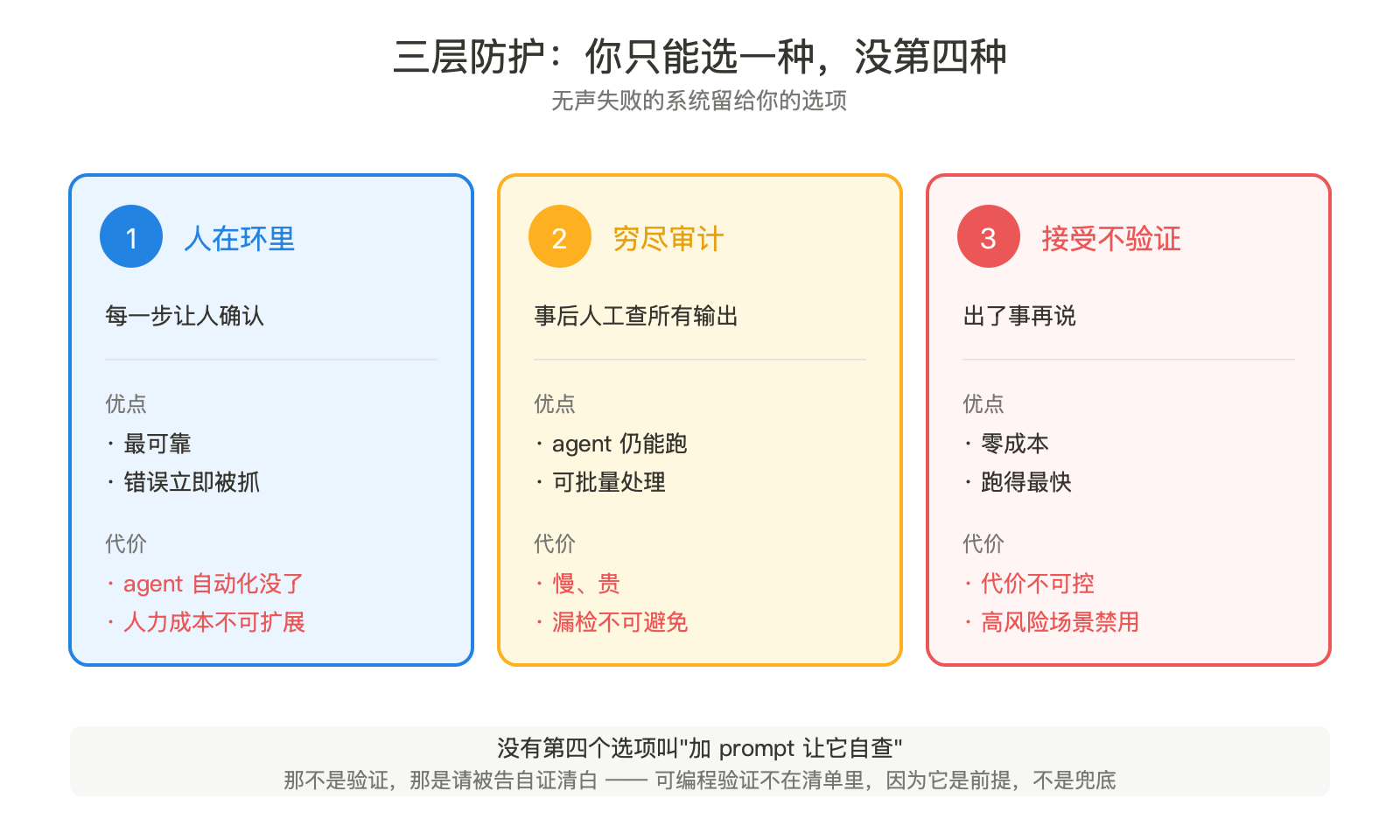
Brian 文章最后一段是干货。会"无声失败"的系统需要主动的错误检测。如果你的 agent 不能在出错时大声叫,你只剩三个选项:
- 人在环里。每一步都让人确认。可靠,但 agent 的意义没了。
- 跑完穷尽审计。事后人工检查所有输出。慢,贵,且漏检。
- 接受不验证。出了事再说。免费,代价不可控。
这是一个被刻意设计成不舒服的清单。Brian 没把"加一段 prompt 让它自己检查自己"列进去。那不是验证,那是请被告自证清白。
可编程验证不在这个清单里,因为它不是兜底,它是前提。如果你能写可编程验证,你已经在 control flow 路线上,根本不需要兜底。
这一段才是文章真正扎心的地方。"prompt 工程能解决一切"这种乐观主义,在这三个选项面前破功。你要么把人塞进去,要么把审计塞进去,要么接受失控。没有第四种舒服的解法。
盲区:我们不知道的
写 control flow 的成本边界。Brian 说"把逻辑搬进运行时",没说这件事多贵。一个 5 步 agent 写成 control flow 可能是两天工作量;一个 50 步 agent 写成 control flow 可能要重写半个产品。这个跨越点在哪?文章没答。
control flow 的脆弱性。代码也会崩。一个 if-else 写错可能让整个 agent 卡死,prompt 写错至少还能跑出个奇怪的答案。Brian 把"确定性"等价于"可靠性"。但确定性的 bug 也是确定性的——一旦写错就稳定地错下去。
"非确定性是缺陷"是不是过头了。LLM 的非确定性在某些场景里不是 bug 是 feature,它能处理你没预想到的输入。一个 100% control flow 的系统就是传统软件,没必要套 agent 这层壳。Brian 没区分"需要 agent 的任务"和"被错配成 agent 的任务"。
为什么是现在。这个观点 2024 年就有人讲过。为什么 Brian 这篇 350 字的便签在 2026 年 5 月炸出 153 条评论?我猜是社区集体撞墙了。过去 12 个月所有人都在加 prompt,加到加不动了。Brian 这篇是泄压阀。
对 AI 从业者意味着什么
如果你在写 agent 项目:今晚 grep 一下你的 codebase,搜 MANDATORY、DO NOT、IMPORTANT、ALWAYS、NEVER。每一个命中点都是一个候选——这一段逻辑能不能用代码表达?大多数时候答案是"能,但我懒"。
如果你在做技术选型:判断一个 agent 框架值不值得用,看它逼你写 prompt 还是逼你写代码。LangGraph、Pydantic AI、Inngest 这类把状态机和验证暴露成一等公民的框架,方向对。把"prompt 模板管理"当核心卖点的框架,方向错。
如果你在带团队:禁止你的工程师把 bug 修在 prompt 里。改 prompt 是没有 reviewable diff 的修改,你看不到行为变化的边界,看不到副作用,看不到回归测试。强制要求:"如果这个 bug 能用代码修,必须用代码修。只有当模型行为本身有问题时,才允许动 prompt。"
一个更深的信号:Brian 这篇文章在 HN 火了,意味着行业的注意力正在从"调教模型"转向"包装模型"。2024 年的明星是会写 prompt 的人,2026 年的明星会是会写 harness 的人。Anthropic 用 Managed Agents 卖 harness,OpenAI 用 Codex 卖 harness。三家头部都在告诉你同一件事:模型这一层没什么可争的了,争的是上面那一层。
哪一层?写代码的那一层。
本期关键词
Control Flow(控制流)。程序里决定"下一步执行什么"的逻辑:if-else、循环、函数调用、异常处理。Brian 主张可靠 agent 的控制流必须写在代码里,而不是写在 prompt 散文里。代码控制流可验证、可单元测试、可静态分析,prompt 控制流三样都没有。
Harness(脚手架)。包裹在 LLM 外面的整套工程基础设施:工具系统、权限管线、状态管理、错误处理、上下文压缩、子 agent 编排。Sebastian Raschka 提"Harness > Model"。模型贡献约 60% 的产品质量,Harness 贡献 40%。Claude Code 是把 Harness 做到极致的代表,50 万行 TypeScript,system prompt 只有 20 个词。
Prompt Engineering(提示词工程)。通过精心设计自然语言指令让 LLM 产出期望输出的实践。Brian 没否定 prompt 工程本身,他否定的是"用 prompt 工程解决控制流问题"。当你开始写 MANDATORY 时,你已经在用错工具。
确定性 / Determinism。给定相同输入,每次输出相同。代码是确定性的,sort([3,1,2]) 永远返回 [1,2,3]。LLM 不是,相同 prompt 两次调用可能给两个答案。Brian 的核心论点:复杂系统必须建立在确定性组件之上,把 LLM 的非确定性局限在不得不用它的那一层。
Silent Failure(无声失败)。系统出错但不报错,错误被吞进下游产生连锁污染。LLM agent 是无声失败的高发区,它不会说"我跳过了第 3 步",它会假装第 3 步做完了继续往下走。这是为什么 Brian 说必须有主动错误检测,而不是依赖事后发现。
Human-in-the-loop(人在环里)。让人在 agent 关键步骤介入确认的工程模式。是 Brian 列的三个兜底之一。可靠,但牺牲了 agent 自动化的核心价值。混合做法是只在高风险节点要求人介入,其他节点用代码验证。
Managed Agents。Anthropic 4 月推出的托管 Agent PaaS,按 session-hour 计费。是"卖 Harness 而不是卖模型"路线最完整的产品化形态。和 Brian 这一篇是一个故事的两面:Brian 说 control flow 要写在代码里,Anthropic 在卖那个写代码的运行时。
引用
- Agents need control flow, not more prompts。本期拆解原文,Brian 在 Bear Blog 发布于 2026-05-07
- Building Effective Agents。Anthropic 工程博客,agent 设计模式经典文献
- Scaling Managed Agents: Decoupling the Brain from the Hands。Anthropic 4 月发布,Harness 工程的产品化
- Harness Engineering。我们知识库里的概念页,Harness > Model 综述